End-to-End Quantum Computing System Design Explained
Qubit counts, coherence times, or gate fidelities too often measure quantum computing progress. While these metrics matter, they are not what determine whether a quantum computer becomes a usable, scalable computing platform. In practice, the limiting factors are almost always system-level: control electronics, firmware, classical–quantum integration, orchestration, and the ability to scale all of these layers together.

This article argues a simple but often uncomfortable thesis: the quantum computing race will be won less by breakthroughs in qubit physics and more by teams that treat quantum computers as integrated systems rather than isolated experiments. Drawing on five years of system-architecture work across superconducting and trapped-ion platforms — and close engagement with both industry and academia — I outline where common assumptions break down, what real-world system design teaches us, and what will matter most over the next five years.
What “End-to-End” Really Means in Quantum Computing
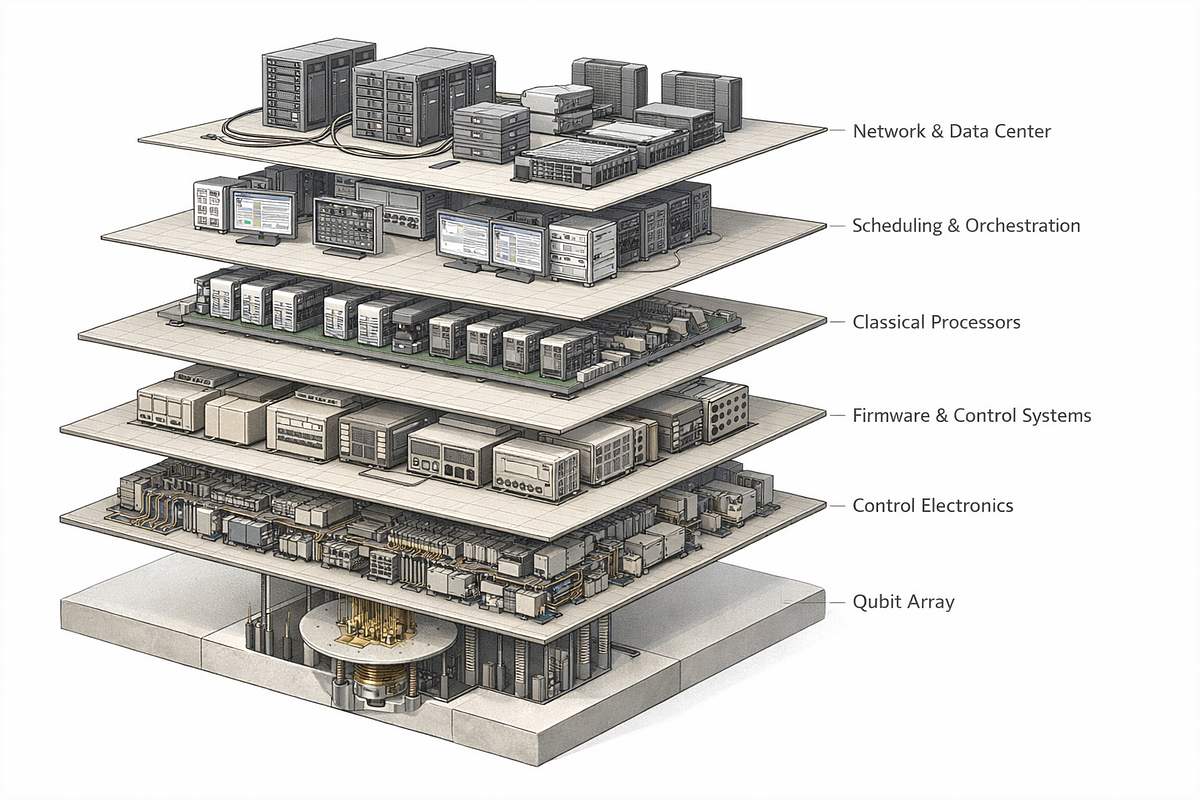
When I refer to an end-to-end quantum computing system, I mean the entire vertically integrated stack, including:
- Physical qubits and their operating environments (cryogenics, vacuum, lasers)
- Control electronics and signal delivery
- Real-time firmware and feedback loops
- Compilers, transpilers, and pulse-level mapping
- Runtime scheduling and orchestration
- Classical co-processing for hybrid algorithms
- Cloud interfaces and user-facing APIs
What is most frequently misunderstood is not the qubits themselves, but the classical and control layers that make qubits usable at scale. These layers dominate integration effort, operational complexity, and ultimately performance.
A quantum computer is not a device — it is a distributed, heterogeneous system operating across radically different timescales, noise regimes, and abstraction layers. Treating any one layer in isolation is a reliable way to stall progress.
Strong Opinions Most Teams Get Wrong
1. “Better Qubits” Are Not the Main Scaling Bottleneck
Improving coherence and gate fidelity is necessary — but it is not sufficient. As systems scale, control complexity, wiring density, calibration overhead, and firmware latency grow faster than qubit quality improves. In practice, a system with slightly worse qubits but superior orchestration and control will outperform a lab-grade array that cannot scale operationally.
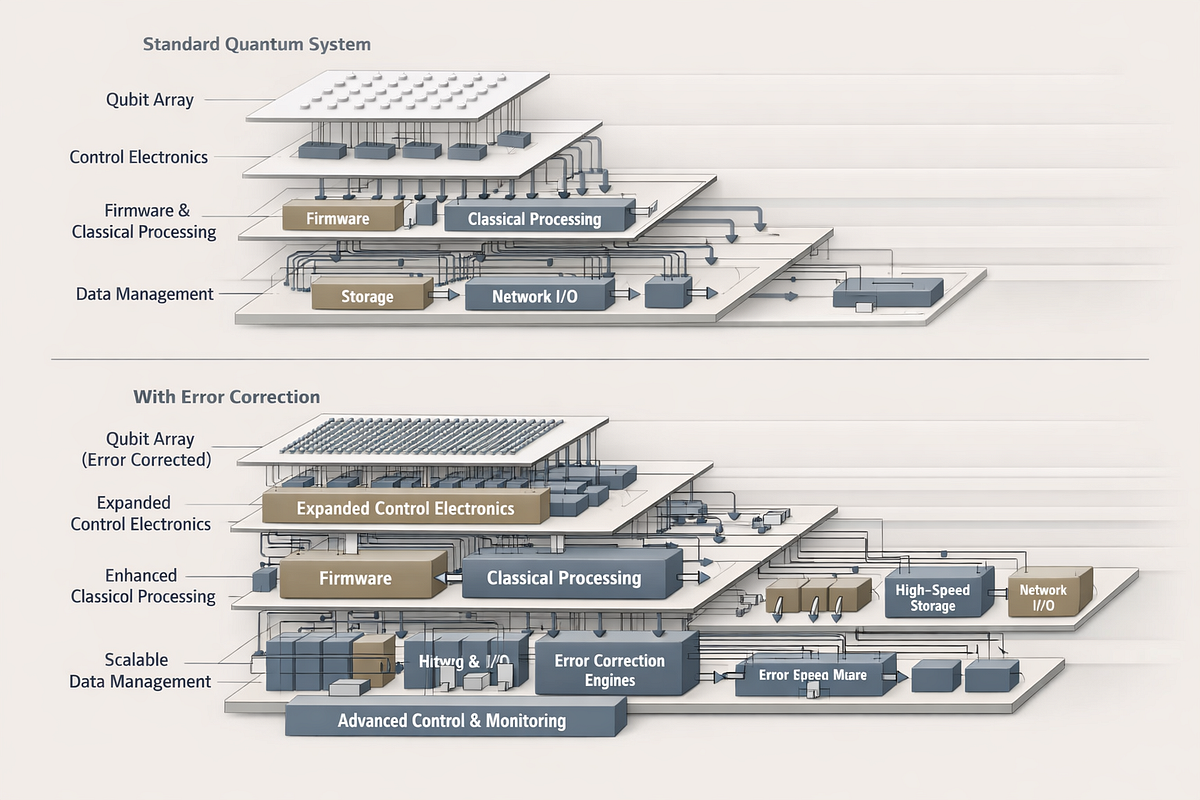
2. Error Correction Is Not a Future Add-On
A common assumption is that teams can build NISQ systems now and “layer in” error correction later. This is fundamentally flawed. Error correction reshapes:
- Qubit layout and connectivity
- Control topologies
- Firmware feedback timing
- Compiler assumptions
- Runtime scheduling
If an architecture cannot host error correction cleanly today, it will not evolve into a fault-tolerant system tomorrow. Error correction is a system redesign, not a software upgrade.
3. Control Electronics Are Treated Like Generic RF Systems
Off-the-shelf RF stacks work for small experiments. They fail at scale. Quantum control demands deterministic timing across thousands of channels, tight phase coherence, cryo-aware routing, and severe power and thermal constraints. Quantum systems fail in cables, racks, and timing jitter — not in Hamiltonians.

4. Firmware Is Treated as Glue Code
Firmware determines feedback latency, calibration speed, error suppression feasibility, and fault-tolerant cycle times. When firmware is treated as an implementation detail rather than a first-class design concern, fault tolerance remains theoretical.
5. Compilers Are Optimized Independently of Hardware
Compiler sophistication cannot compensate for inflexible hardware. Without hardware-aware co-design, routing overhead explodes, circuit depth negates fidelity gains, and compilation time dominates execution. A beautiful compiler targeting an inflexible device is still bottlenecked by physics.
6. Classical–Quantum Integration Is Underestimated
Latency, data movement, and orchestration determine whether hybrid algorithms converge and whether throughput scales. Near-term quantum advantage is largely a classical systems problem, not an algorithmic one.

7. Cloud Access Is Mistaken for System Maturity
An API does not make experimental hardware a computing platform. True maturity requires reproducibility, predictable performance, resource isolation, and cross-layer debugability. Cloud access is a distribution mechanism — not a proxy for readiness.
Vertical Integration at the Core, Modularity at the Interfaces
My position is deliberately unambiguous: quantum systems must be vertically integrated at their core, with carefully designed modular boundaries at the edges.
Pure modularity is a luxury of mature platforms. Quantum computing today is pre-standard, noise-dominated, and rapidly evolving. In this regime:
- Abstractions leak constantly
- Latency and fidelity trump portability
- Cross-layer assumptions matter
Vertical integration enables co-design; co-design enables scaling.

That said, modularity does belong at well-defined interfaces:
- Control APIs
- Compiler IR boundaries
- Runtime scheduling interfaces
- Cloud access layers
What does not work is importing cloud-native modularity too early and pretending qubits, control, firmware, and compilers are loosely coupled components. They are not.
Why Hardware-Aware Software Wins (For Now)
Hardware-agnostic abstractions promise portability, but today they mostly deliver performance loss. They hide topology constraints, inflate circuit depth, and obscure failure modes. In quantum computing, abstraction without hardware awareness is often abstraction without performance.
Hardware-agnostic layers make sense for education, onboarding, and algorithm prototyping. For deployable systems and near-term value, every meaningful layer must understand the hardware it runs on.
A concise way to state this reality:
Quantum computing today demands vertical integration and hardware-aware software; modular, hardware-agnostic stacks become viable only once fault tolerance and standardization arrive.
Case Study: Scaling a Cloud-Accessible Superconducting Testbed
I worked on the design and integration of a cloud-accessible superconducting quantum testbed intended for hybrid algorithm research. The goal was to connect qubit hardware, control electronics, real-time firmware, compilers, runtime orchestration, and a developer-facing cloud interface into a usable system.
The hardest tradeoff was balancing control fidelity, latency, and scalability. Improving gate fidelity often required longer calibration routines and more complex pulses, which increased latency and strained firmware and classical co-processing. Scaling from small experiments to 30–50 qubits exposed bottlenecks in wiring density, timing jitter, and feedback determinism.
The original control electronics and firmware stack — designed for small-scale fidelity — had to be largely redesigned. Firmware could not initially handle real-time pulse sequencing and feedback at scale, limiting throughput and breaking error mitigation experiments. Only after re-architecting the electronics layout and firmware together did the system become operationally scalable.

The lesson was clear: no layer can be designed in isolation. System behavior only becomes visible at scale, and cross-layer dependencies dominate outcomes.
Where the Real Complexity Lives
Despite the focus on qubits, most system complexity lives in the classical layers: control electronics, firmware, compilers, orchestration, and cloud infrastructure. Low-latency classical feedback is a cornerstone of practical quantum computing. Without it, hybrid algorithms stall, and early error correction fails.
Teams consistently underestimate these layers, treating them as plumbing rather than as performance-critical infrastructure. This mistake alone can negate years of qubit-level progress.
Error Mitigation vs. Error Correction: A System View
Error mitigation is the near-term priority. It leverages software and firmware to reduce effective noise without adding qubits. Error correction is a long-term architectural driver that reshapes the entire system.
The largest gap between theoretical fault tolerance and deployable systems is not code design — it is cross-layer integration. Latency, calibration, routing, and classical processing routinely destroy theoretical advantages if any layer underperforms.
Most current roadmaps underestimate this reality. Fault tolerance is as much a systems engineering challenge as it is a physics challenge.
What’s Missing in Today’s Quantum Stacks
Many platforms excel at isolated layers — qubit access, SDKs, or cloud APIs — but lack true end-to-end co-design. Missing capabilities include:
- Scalable, deterministic control architectures
- Firmware designed for real-time feedback at scale
- Cross-layer optimization and observability
- Runtime systems built for hybrid workloads
Until these gaps are addressed, qubit count alone will not translate into usable computation.
A Five-Year Outlook: What Will Matter More — and Less
What will matter less than expected: raw qubit count and headline gate fidelity.
What will matter far more: system-level integration — low-latency feedback, scalable control electronics, firmware co-design, hardware-aware compilers, and hybrid runtime orchestration.
Five years from now, well-designed quantum systems will be judged not by how many qubits they have, but by whether they reliably deliver usable, hybrid quantum–classical applications.
Final Thought
“Full-stack quantum” is not a product category. It is an ongoing systems engineering discipline. Teams that recognize this — and design accordingly — will be the ones that turn quantum computing from an experimental curiosity into a deployable technology.




Comments
Post a Comment